| Version 8 (modified by , 10 years ago) ( diff ) |
|---|
Subsets in Petascope
In this page we will describe how subsets (trims and slices) are treated by Petascope. Before this you will have to understand how the topology of a grid coverage is interpreted with regards to its origin, its bounding-box and the assumptions on the sample spaces of the points. Some practical examples will then be proposed.
Geometric interpretation of a coverage
This section will focus on how the topology of a grid coverage is stored in the metadata database and how Petascope interprets it. For point-clouds (multipoint coverages, in the GML realm), the subject is straightforward: each point is a 0D element (please not that bbox description of point-clouds are currently not implemented: see #571).
When it comes to the so-called domainSet of a coverage (hereby also called domain, topology or geometry), the metadata database (petascopedb) follows pretty much the GML model for rectified grids: the grid origin and one offset vector per grid axis are enough to deduce the full domainSet of such (regular) grids. When it comes to referenceable grids, the domainSet still is kept in a compact vectorial form by adding weighting coefficients to one or more offset vectors. For more on coefficients refer to the [PetascopeUserGuide user guide].
- What is a grid?
- As by GML standard a grid is a "network composed of two or more sets of curves in which the members of each set intersect the members of the other sets in an algorithmic way". The intersections of the curves are represented by points: a point is 0D and is defined by a single coordinate tuple (see ISO:19107
GM_Point).
A first question arises on where to put the grid origin. The GML and GMLCOV standards say that the mapping from the domain to the range (feature space, payload, values) of a coverage is specified through a function, formally a gml:coverageFunction. We do not currently support the configuration of such function, whereas we stick to the default mapping which is indeed assumed when no coverage function is described. From the GML standard: "If the gml:coverageFunction property is omitted for a gridded coverage (including rectified gridded coverages) the gml:startPoint is assumed to be the value of the gml:low property in the gml:Grid geometry, and the gml:sequenceRule is assumed to be linear and the gml:axisOrder property is assumed to be +1 +2".
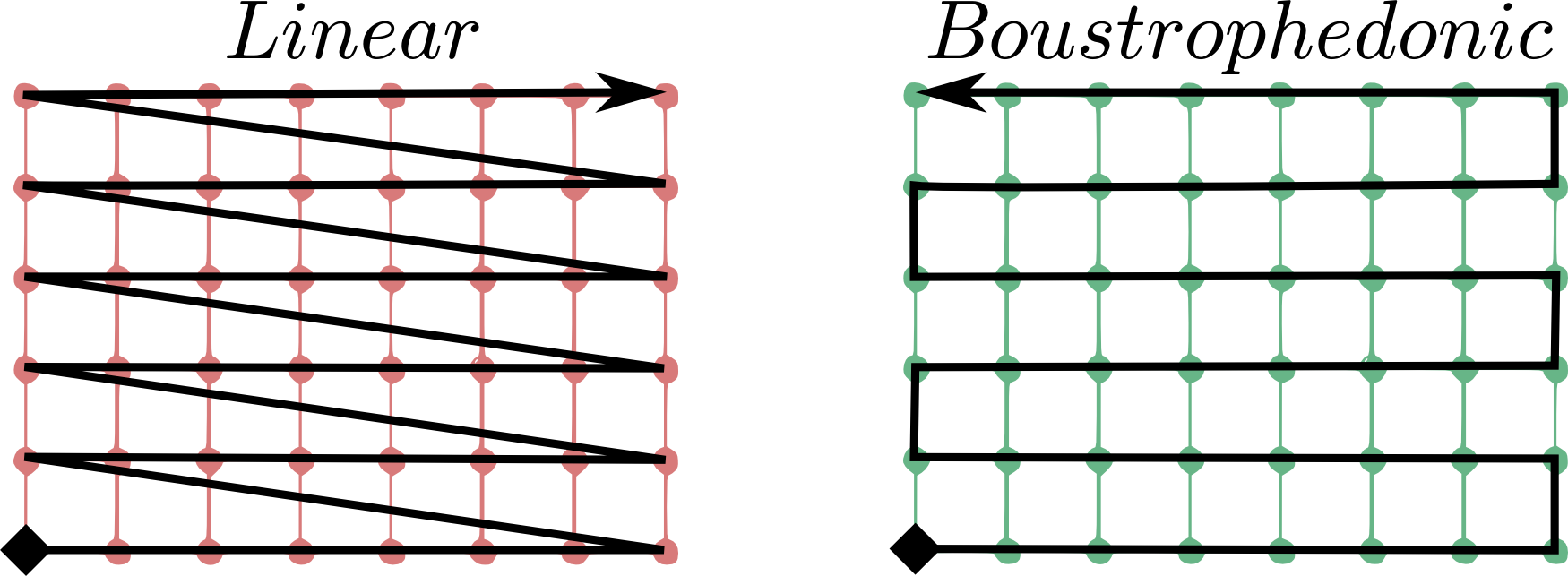
To better understand this, the following image is showing the difference between a linear sequence rule (what we adopt) and an other kind of mapping, the so-called boustrophedonic (check out this page for other available rules):

In the image, it is assumed that the first grid axis (+1) is the horizontal axis, while the second (+2) is the vertical axis; the grid starting point is the full diamond.
Sticking to the linear sequence rule was the best choice for rasdaman since that is the same rule which rasdaman itself uses to print the values of cells in an collection/marray.
Coming back to the origin question on where to put the origin of our grid coverages, we have to make it coincide to what the starting value represents in rasdaman, the marray origin.
As often done in GIS applications, the origin of an image is set to be its upper-left corner: this finally means that the origin of our rectified and referenceable grid coverages shall be there too in order to provide a coherent GML/GMLCOV coverage, where the domain is really mapped to the range of the coverage with the default coverage function. Note that placing the origin in the upper-left corner of an image means that the offset vector along the northing axis will point South, hence will have negative norm (in case the direction of the CRS axis points North!).
When it comes to further dimensions (a third elevation axis, time, etc.), the position of the origin depends on the way data has been ingested. Taking the example of a time series, if the marray origin (which we can denote as [0:0:__:0], though it is more precisely described as [dom.lo[0]:dom.lo[1]:__:dom.lo[n]) is the earliest moment in time, then the grid origin will be the earliest moment in the series too, and the offset vector in time will point to the future (positive norm); in the other case, the origin will be the latest time in the series, and its vector will point to the past (negative norm).
To summarize, in any case the grid origin must point to the marray origin. This is important in order to properly implement our linear sequence rule.
A second question arises on how to treat coverage points: are they points or are they areas? The formal ISO term for the area of a point is sample space. We will refer to it as well as footprint or area. The GML standard provides guidance on the way to interpret a coverage: "When a grid point is used to represent a sample space (e.g. image pixel), the grid point represents the center of the sample space (see ISO 19123:2005, 8.2.2)".
In spite of this, there is no formal way to describe GML-wise the footprint of the points of a grid. While the configuration of sample spaces is still just on our wishlist (see #680), our current policy applies distinct choices separately for each grid axis, in the following way:
- regular axis: when a grid axis has equal spacing between each of its points, then it is assumed that the sample space of the points is equal to this spacing (resolution) and that the grid points are in the middle of this interval;
- irregular axis: when a grid axis has an uneven spacing between its points, then there is no (currently implemented) way to either express or deduce its sample space, hence 0D points are assumed here (no footprint).
Such policy is translated in practice to a point-is-pixel-center interpretation of regular rectified images. The following art explains it visually:
KEY
# = grid origin o = pixel corners
+ = grid points @ = upper-left corner of BBOX
{v_0,v_1} = offset vectors
|======== GRID COVERAGE MODEL =========| |===== GRID COVERAGE + FOOTPRINTS =====|
{UL}
v_0 @-------o-------o-------o-------o--- -
--------> | | | | |
. #-------+-------+-------+--- - | # | + | + | + |
v_1 | | | | | | | | | |
| | | | . o-------o-------o-------o-------o-- -
V | | | . | | | | .
+-------+-------+--- - | + | + | + | .
| | | | | | |
| | . o-------o-------o-------o-- -
| | . | | | .
+-------+--- - | + | + . .
| | | | .
| . o-------o--- -
| . | .
+--- - . + .
. .
.
|======================================| |======================================|
The left-side grid is the GML coverage model for a regular grid: it is a network of (rectilinear) curves, whose intersections determine the grid points '+'. The description of this model is what petascopedb knows about the grid.
The right-hand grid is instead how Petascope inteprets the information in petascopedb, and hence is the coverage that is seen by the enduser. You can see that, being this a regular grid, sample spaces (pixels) are added in the perception of the coverage, causing an extension of the bbox (gml:boundedBy) of half-pixel on all sides. The width of the pixel is assumed to be equal to the (regular) spacing of the grid points, hence each pixel is of size |v_0| x |v_1|, being |*| the norm operator.
As a final example, imagine that we take this regular 2D pattern and we build a stack of such images on irregular levels of altitude:
KEY
# = grid origin X = ticks of the CRS height axis
+ = grid points O = origin of the CRS height axis
{v_0,v_2} = offset vectors
O-------X--------X----------------------------X----------X-----X-----------> height
|
| ---> v_2
| . #________+____________________________+__________+_____+
| v_0 | | | | | |
| V +________+____________________________+__________+_____+
| | | | | |
| +________+____________________________+__________+_____+
| | | | | |
| +________+____________________________+__________+_____+
| | | | | |
V . . . . .
easting
In petascopedb we will need to add an other axis to the coverage topology, assigning a vector 'v_2' to it (we support gmlrgrid:ReferenceableGridByVectors only, hence each axis of any kind of grid will have a vector). Weighting coefficients will then determine the height of each new z-level of the cube: such heights are encoded as distance from the grid origin '#' normalized by the offset vector v_2. Please note that the vector of northings v_1 is not visible due to the 2D perspective: the image is showing the XZ plane.
Regarding the sample spaces, while Petascope will still assume the points are pixels on the XY plane (eastings/northings), it will instead assume 0D footprint along Z, that is along height: this means that the extent of the cube along height will exactly fit to the lowest and highest layers, and that input Z slices will have to select the exact value of an existing layer.
The latter would not hold on regular axes: this is because input subsets are targeting the sample spaces, and not just the grid points, but this is covered more deeply in the following section.
Input and output subsettings
This section will cover two different facets of the interpretation and usage of subsets: how they are formalized by Petascope and how they are adjusted.
Trimming subsets 'lo,hi' are mainly covered here: slices do not pose many interpretative discussions.
A first point is whether an interval (a trim operation) should be (half) open or closed. Formally speaking, this determines whether the extremes of the subset should or shouldn't be considered part of it: (lo,hi) is an open interval, [lo.hi) is a (right) open interval, and [lo,hi] is a closed interval.
Requirement 38 of the WCS Core standard (OGC 09-110r4) specifies that a /subset/ is a closed interval.
A subsequent question is whether to apply the subsets on the coverage points or on their footprints. While the WCS standard does not provide recommendations, we decided to target the sample spaces, being it a much more intuitive behavior for users who might ignore the internal representation of an image and do not want to lose that "half-pixel" that would inevitably get lost if footprints were to be ignored.
We also consider here "right-open sample spaces", so the borders of the footprints are not all part of the footprint itself: this means that two adjacent footprints will not share the border, which will instead belong to the greater point (so typically on the right side in the CRS space). A slice exactly on that border will then pick the right-hand "greater" point only . Border-points instead always include the external borders of the footprint: slices right on the native BBOX of the whole coverage will pick the border points and will not return an exception.
Clarified this, the last point is how coverage bounds are set before shipping, with respect to the input subsets. That means whether our service should return the request bounding box or the minimal bounding box.
Following the (strong) encouragement in the WCS standard itself (NOTE paragraph to requirement 38), Petascope will fit the input subsets to the extents of sample spaces (e.g. to the pixel areas), thus returning the minimal bounding box. This means that the input bbox will usually be extended to the next footprint border. This is also a consequence of our decision to apply subsets on footprints: a value which lies inside a pixel will always select the associated grid point, even if the position of the grid point is actually outside of the subset interval.
Please note that before version 9.0 of rasdaman the request bounding box is returned instead by Petascope.
Practical examples will now follow. For open discussions on the policies we adopted, you are suggested to reply to this post in our mailing list.
Examples
In this section we will examine the intepretation of subsets by Petascope by taking different subsets on a single dimension of 2D coverage. To appreciate the effect of sample spaces, we will first assume regular spacing on the axis, and then irregular 0D-footprints.
Test coverage information:
-------------------- mean_summer_airtemp (EPSG:4326) Size is 886, 711 Pixel Size = (0.050000000000000,-0.050000000000000) Upper Left ( 111.9750000, -8.9750000) Lower Left ( 111.9750000, -44.5250000) Upper Right ( 156.2750000, -8.9750000) Lower Right ( 156.2750000, -44.5250000) --------------------
From this geo-information we deduce that the grid origin, which has to be set in the upper-left corner of the image, in the centre of the pixel are, will be:
origin(mean_summer_airtemp) = [ (111.975 + 0.025) , (-8.975 - 0.025) ]
= [ 112.000 , -9.000 ]
It is also reminded that Petascope will display [-9,112] as grid origin, since it strictly follows the order of axis defined in the WGS84 CRS. See this OGC policy and our [PetascopeUserGuide user guide] for more insights.
Regular axis: point is area
KEY
o = grid point
| = footprint border
[=s=] = subset
[ = subset.lo
] = subset.hi
_______________________________________________________________________
112.000 112.050 112.100 112.150 112.200
Long: |----o----|----o----|----o----|----o----|----o----|-- -- -
cell0 cell1 cell2 cell3 cell4
[s1]
[== s2 ===]
[== s3 ==]
[==== s4 ====]
[== s5 ==]
_______________________________________________________________________
s1: [112.000, 112.020]
s2: [112.025, 112.075]
s3: [112.025, 112.070]
s4: [112.010, 112.070]
s5: [111.950, 112.000]
Applying these subsets to mean_summer_airtemp will produce the following responses:
| GRID POINTS INCLUDED | OUTPUT BOUNDING-BOX(Long)
-----+----------------------+----------------------------
s1 | cell0 | [ 111.975, 112.025 ]
s2 | cell1, cell2 | [ 112.025, 112.125 ]
s3 | cell1 | [ 112.025, 112.075 ]
s4 | cell0, cell1 | [ 111.975, 112.075 ]
s5 | cell0 | [ 111.975, 112.025 ]
Irregular axis: point is point
KEY
o = grid point
[=s=] = subset
[ = subset.lo
] = subset.hi
_______________________________________________________________________
112.000 112.075 112.110 112.230
Long: o-------------o--------o-----------------o--- -- -
cell0 cell1 cell2 cell3
[s1]
[== s2 ===]
[== s3 ==]
[======= s4 =======]
[== s5 ==]
_______________________________________________________________________
s1: [112.000, 112.020]
s2: [112.010, 112.065]
s3: [112.040, 112.090]
s4: [111.970, 112.090]
s5: [111.920, 112.000]
Applying these subsets to mean_summer_airtemp will produce the following responses (please note tickets #681 and #682):
| GRID POINTS INCLUDED | OUTPUT BOUNDING-BOX(Long)
-----+----------------------+----------------------------
s1 | cell0 | [ 112.000, 112.000 ]
s2 | --- (WCSException) | [ --- ]
s3 | cell1 | [ 112.075, 112.075 ]
s4 | cell0, cell1 | [ 112.000, 112.075 ]
s5 | cell0 | [ 112.000, 112.000 ]
EOF.
Attachments (1)
-
sequenceRules.png
(106.6 KB
) - added by 10 years ago.
Explanation of the linear sequence rule.
{kind=link}
Download all attachments as: .zip